Reading A few notes on distributed computing with PyTorch
On using multiple GPUs
Before you consider using more than 1 GPU on Compute Canada clusters, you should carefully analyze whether this will truly benefit your model.
With the explosion of the field of machine learning in recent years, the GPUs in Compute Canada clusters have seen an exponential increase in demand. Resources are expanding, but cannot keep up.
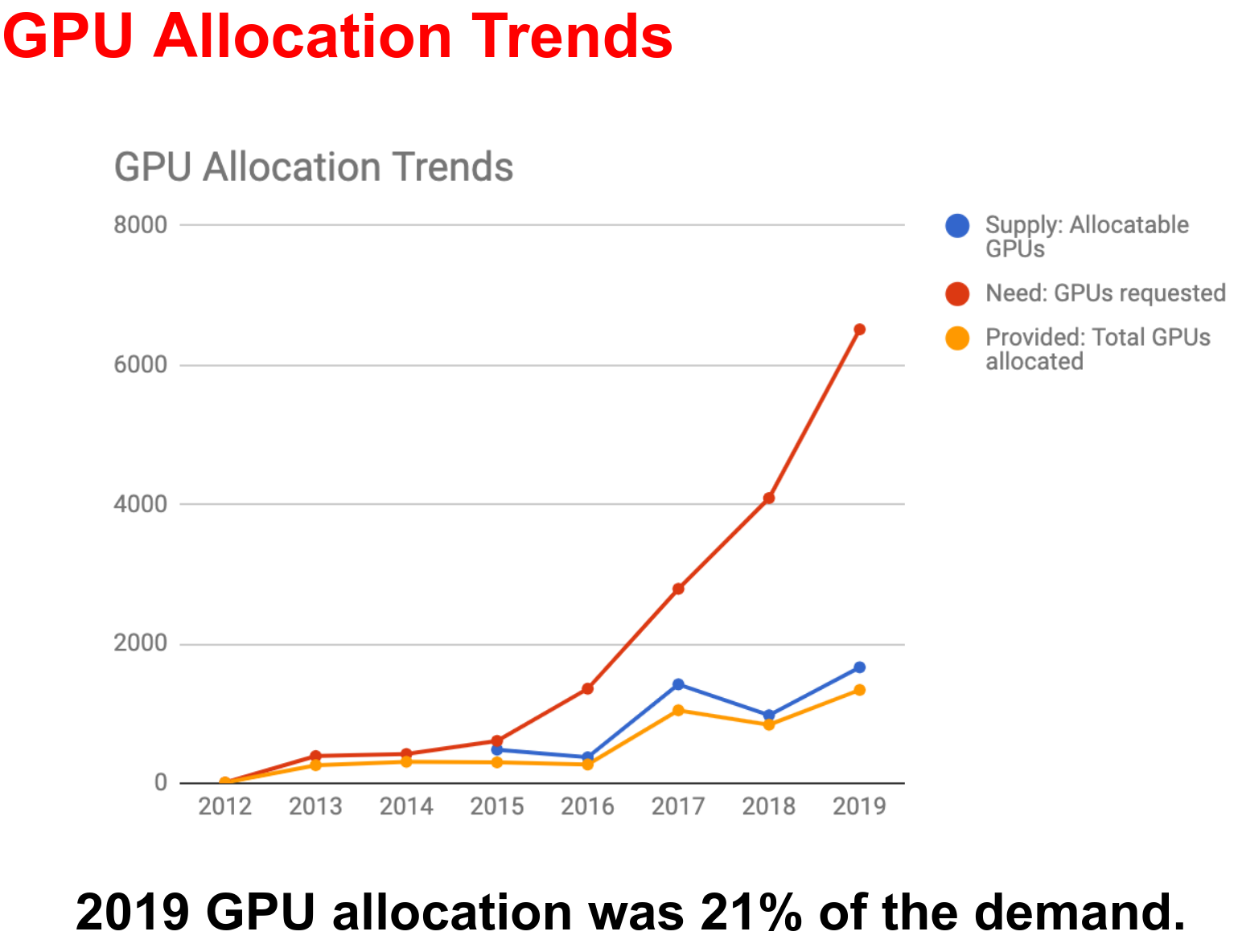
If you ask for more GPUs, you will wait a lot longer and you will go through your GPU allocation quickly.
In many cases, this will not make your model faster: PyTorch, by default, only uses one GPU.
There are however situations when multiple GPUs are advantageous, or even necessary. So you need to learn when and how to parallelize your code to use multiple GPUs.
If you are in doubt, while you are learning, and when testing code, stick to a single GPU.
Distributed computing with PyTorch is beyond this introductory course in machine learning. The main message here is that throwing multiple GPUs at your model is a loss of resource if you don't know what you are doing. We will offer workshops on distributed ML in the future, but in the meantime, here are the main scenarios with some links to tutorials.
Data parallel
Single node (or single machine), single process, multi-thread (multiple GPUs).
PyTorch allows to run the same model on multiple GPUs, each GPU using a different partition of the data. Since each GPU runs the model on a fraction of the data, you get a speedup in training.
This is done with torch.nn.DataParallel .
DataParallel splits the data automatically and sends jobs to the GPUs: each GPU gets a different data partition and runs the model on it. Once all the jobs are done, DataParallel collects and compiles the results before returning the final output.
For instance, if you have a mini-batch of size \(m\) and 2 GPUs. DataParallel sends \(m/2\) samples to one GPU and the other \(m/2\) samples to the other. Once they have run the model on that data, DataParallel collects, compiles and returns the result.
Here is an example.
Model parallel
Single node (or single machine), single process, multi-thread (multiple GPUs).
If the model is too large to fit on a single GPU, you need to use model parallel. The model is then split between different GPUs.
You can find an example here.
Distributed data parallel (DDP)
Single or multiple node(s), multiple processes.
Each process handles a split of the data.
This is done with torch.nn.parallel.DistributedDataParallel .
This tutorial walks you through an example.